Note: This was originally intended to be a short tutorial for students in my Data Journalism class that would be both a primer for basic data mashing concepts and a practical walkthrough for the latest iteration of Google Fusion Tables.
Here’s the visual summary for this very long tutorial: We will start with this spreadsheet of New York Health Dept. inspections…
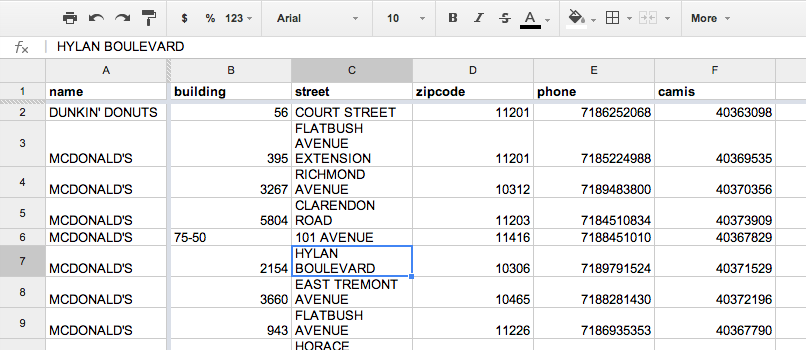
…And produce this interactive map
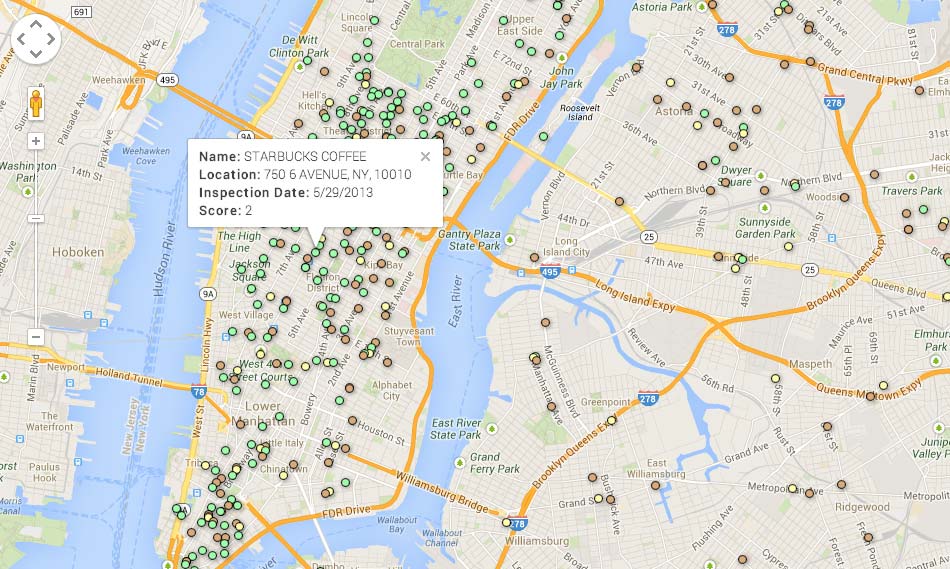
(Note: This is just a non-interactive screenshot; Visit the full interactive page is here)
If you’re new to data analysis and visualization, this guide is (hopefully) for you. It covers the most recent overhaul of Google Fusion Tables in 2013 but the concepts are meant to be universal. It starts with how to upload a CSV file and ends with how to properly categorize your data in a published interactive map.
Table of contents
- Prerequisites and Background
- Transforming data in Google Spreadsheets
- Mapping data with Fusion Tables
- Merging data with Fusion Tables
- Summarizing data with Fusion Tables
- Data wrangling with Google Spreadsheets
- Lookup tables
- More map classification
- Publishing
- The next iteration
Prerequisites and Background
The tools
You must have a Google Account as we’ll be using two of their cloud-based spreadsheet-like applications:
- Google Spreadsheets: This will be most familiar to you if you’ve ever used Excel – in fact, you can use Excel if you prefer. For this lesson, we use Spreadsheets to transform our data set before we visualize it.
- Google Fusion Tables: This uses the same structured data as Spreadsheets, but allows you to merge different data tables together. It’s not as full-featured as your typical database software. But it is easy to use even without knowing any programming and will give you a sense of how powerful data work can be. Also, Fusion Tables makes it extremely easy to create and publish interactive maps (whether the data should be mapped is another question)
Though these are two different programs, they both can export and import to comma-delimited text files. In fact, I would argue that understanding CSVs (rather, delimitation in general), is the most important and universal thing to know when doing data work. I won’t be going into detail about the principles of delimitation, but I’ll walk you through the import and exporting process.
Just remember that the data here is just text, and if you want to get from one application to the other, export as CSV and then, in your destination application, import as CSV.
About the DOH data
For the purposes of this guide, I’m using a subset of restaurant inspections data from the New York Department of Health and Mental Hygiene You can view their interactive site here. You can also get your own copy of their data at NYC’s data portal, though it will not be as cleaned up as it is here.
Structure of the data
There are two tables we’ll be using:
restaurants- This primarily contains business information, such as business name and address. Download it here.inspections- This contains the results of inspections conducted by the DOH, including the inspection date and the numerical score awarded (lower is better). Download it here
Limitations of the data
Some of the changes and limitations in this data include:
- The
restaurantstable only includes Starbucks, Dunkin Donuts, and McDonald’s locations. It’s not to pick on these chains or anything, but there just happens to be a lot of them to look through. And you’ve probably been to at least one of them for coffee and breakfast in your life. - The
inspectionstable only includes the latest inspections per restaurant, as of early October 2013. Some of the places may have been re-inspected since then, so do not assume that the scores here reflect the restaurant’s latest status. Again, check out the NYDOH site for the latest results. - I’ve left out the
violationstable for a future lesson. You’ll have to look at the DOH site to see the details of the violations.
Disclaimer note: You’re welcome to access the data tables and make copies. However, you must accept that this data is presented as is for a class exercise, and is not meant for production and publishing beyond a proof of concept. I make no claims for the accuracy or integrity of this data and you assume all liability and sole responsibility for verifying and correcting the data.
Transforming data in Google Spreadsheets
Start out by downloading the CSV text file of DOH-inspected businesses from this link I’ve provided.
You can open it in Excel if you’d like. I encourage you to open it with a plain text editor to verify that it indeed is just text:
name,building,street,zipcode,phone,camis
DUNKIN' DONUTS,56,COURT STREET,11201,7186252068,40363098
MCDONALD'S,395,FLATBUSH AVENUE EXTENSION,11201,7185224988,40369535
MCDONALD'S,3267,RICHMOND AVENUE,10312,7189483800,40370356
MCDONALD'S,5804,CLARENDON ROAD,11203,7184510834,40373909
You can get to Google Spreadsheets by visiting https://drive.google.com
Click the big red button labeled Create and pick Spreadsheet.
Importing a CSV
You’ll be greeted with an empty table. That’s OK, we already have data. Click the File menu and then Import
You will be asked to Choose File and the Import action. Select the CSV file you just downloaded and then select the Replace current sheet option (it’s empty anyway, so no harm).
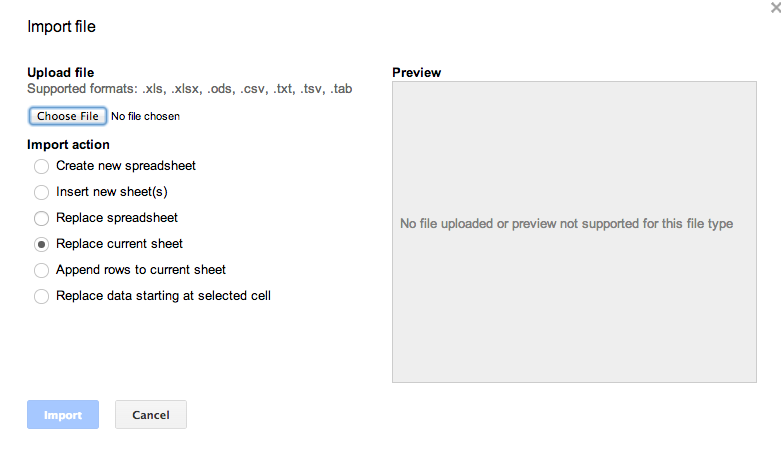
A little animation effect will pop up and you’ll see a preview of the spreadsheet data:
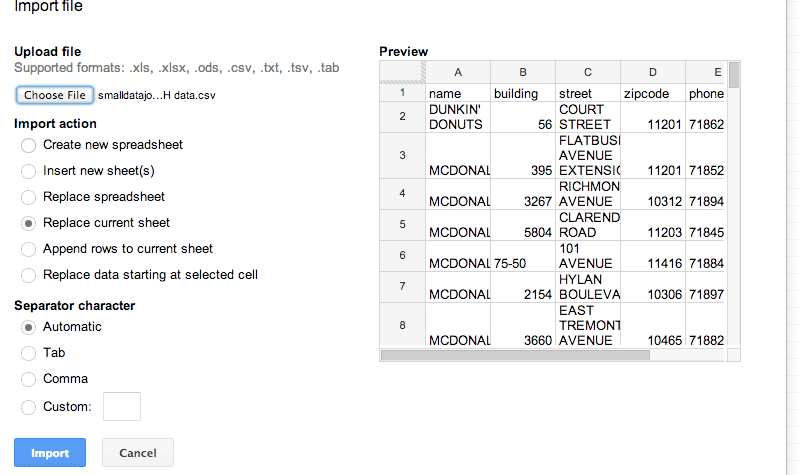
Click the blue Import button and you’ll see your new data:
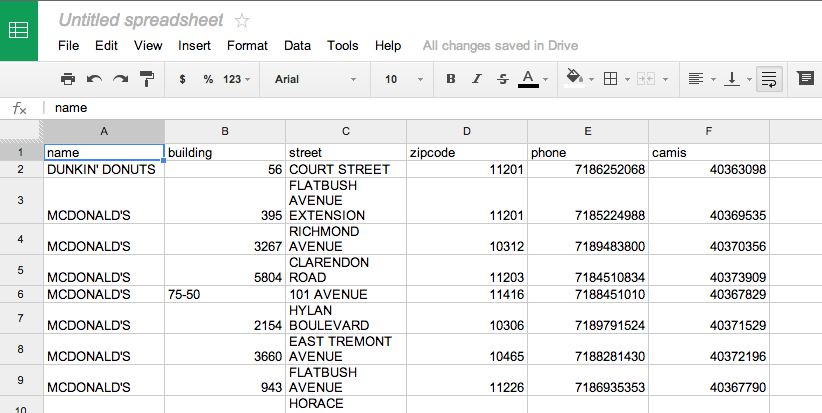
Freezing rows and sorting columns
If you’ve ever used Excel, Google Spreadsheets should seem very familiar to you. Much of Excel’s intermediate-level functionality is here. That, plus the ability to collaborate and share data in real time, from any workstation, makes Google Spreadsheets one of the greatest tools for data journalism today, in my humble opinion.
Freeze rows
But small steps first. One of the things I like about Google’s flavor of spreadsheets is that sorting-by-column is slightly more intuitive. Before we sort, let’s freeze the headers to keep them in place:
Go to the View menu in the Spreadsheets toolbar and select Freeze Rows. Then select Freeze 1 row.
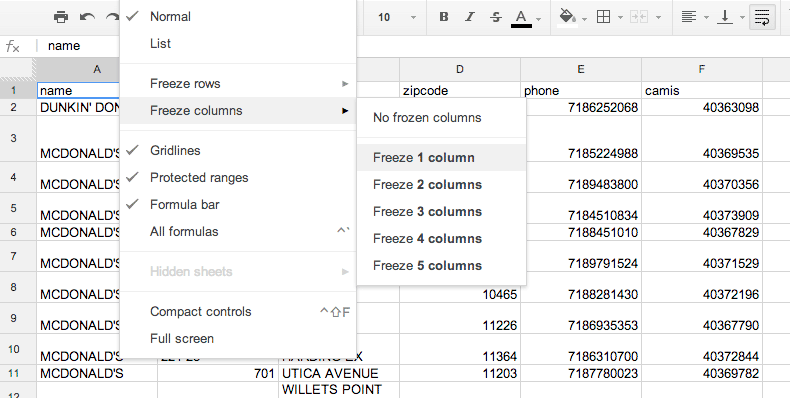
The result of this is now you can scroll the data up and down and the headers will stay in place.
Sort columns
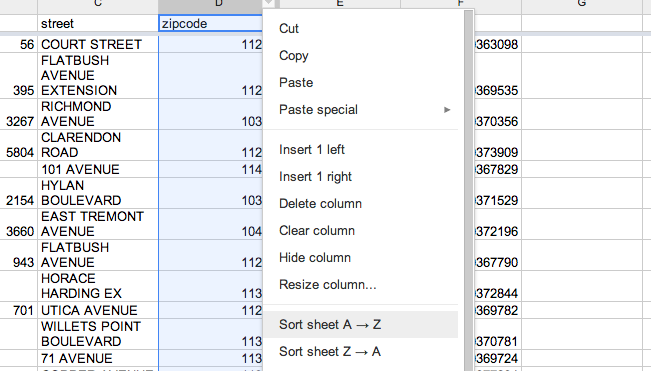
To sort a column, simply click on a column header. As you mouse over it, a little down arrow should appear:
![]()
Click on it to bring up dropdown menu. Choosing Sort sheet A->Z will order things alphabetically, or, if they’re numbers, from smallest to largest:
Preparing our data for mapping
OK, now let’s make our data a bit more interesting. Or, at least more useful.
As I said at the start of this chapter, we want to map this data. Google Spreadsheets does not have this capability built-in. But Spreadsheets is great for getting the data ready for Fusion Tables, which can create an interactive map.
How does Fusion Tables does that? Let’s see how its sister product, Google Maps, does it.
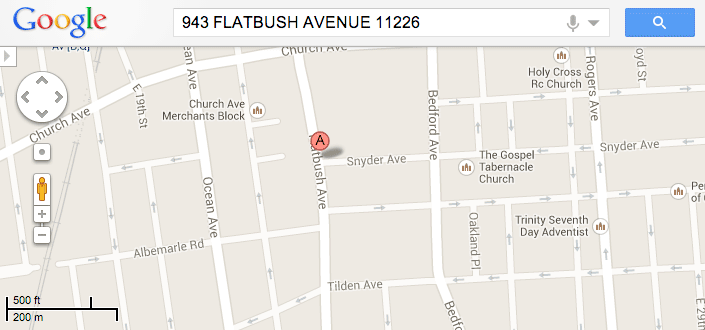
For example, from one of the MCDONALD'S row, we can use the columns for building, street, and zipcode to get something that Google Maps can interpret:
943 FLATBUSH AVENUE 11226
Entering that into Google Maps gets you this:
So to get Fusion Tables to map all of our points, we just need to send over the address information. One big caveat, however: The address data needs to be in one field (or two, if you have latitude and longitude data, which we don’t). But our address data is in three fields: building, street, zipcode
Formula-based columns
So how do we get our three location-related fields into one? Well, we can type them in manually, for all 1,000+ addresses…
There must be a better way, right? There is, but when it comes to computerized data work, you should always try it the old-fashioned way, at least once.
For starters, it helps you appreciate computers. But more importantly, it let’s you understand in human terms what you need the computer to do for you. So if you’ve typed in the building, street, and zipcode data for at least one row, then you can describe the task in human terms:
We simply want to join the three fields together in one.
And luckily, Google Spreadsheets (and Excel) has a way to automate it for us. We just have to describe the above statement in computer terms. And we do this with a formula
Formula basics
First, double-click on an empty cell in one of the empty columns in your spreadsheet.
To create a formula in Google Spreadsheets, start off with an equals sign. This is absolutely critical – if you do not use an equals sign, Spreadsheets will just assume you’re writing in regular text.
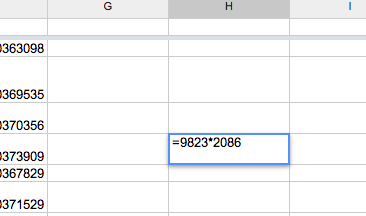
OK, now after typing in an equals sign, type in something formula-ish. Like, 9823*2086 and then hit Enter
(again, remember the equals sign at the beginning)
When you hit Enter, Spreadsheets will calculate your formula and give you an answer. In this case, it’s 20490778
Now double-click on the cell again, you should see your formula as its contents, not the number 20490778:
=9823*2086
Formulas with other cells
Typing in numbers manually isn’t very fun. So let’s add up numbers already in a data. First, choose a row, any row. Row 5, for example, will be just fine.
Now if your data is ordered like my data, the zipcode and phone fields are in columns lettered D and E respectively.
So double-click another empty cell, preferably in Row 5 (though not necessarily), and enter this in:
=D5 + E5
When you refer to specific cells by their column letters and row numbers, Spreadsheets knows that you’re trying to add those two cells together:
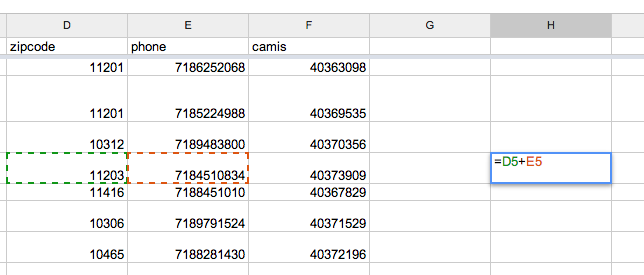
In my case, the values in zipcode and phone for Row 5 were 11203 and 7184510834, respectively. The sum of those two numbers is 7184522037, which is the result of the formula =D5 + E5.
The CONCATENATE function
So how do formulas help us with our original goal? What we need to do is actually kind of math-like: we need to add three fields together, except they contain text, not numbers. However, we can’t use simple + signs for our formula.
Instead, we need to use a special function named CONCATENATE.
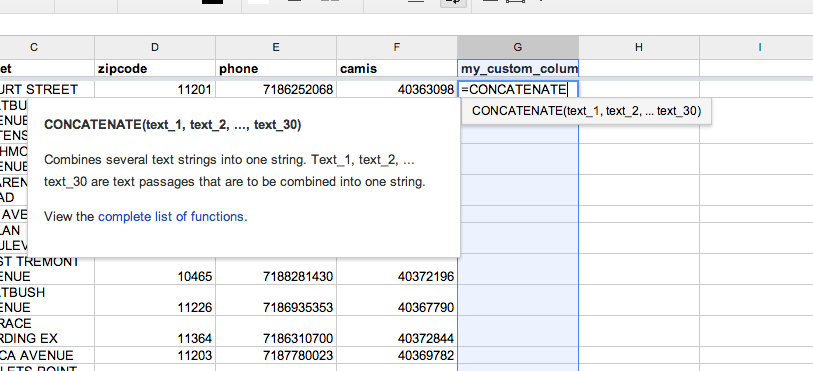
Functions in Google Spreadsheets have a few conventions:
- Again, like any other formula, you must begin with an
=sign - After the name of the function (
CONCATENATE, for example), you pass in the required parameters between parentheses - You use commas to separate the parameters
What do I mean by parameters? Think of them as the values you want the function to act upon. The parameters for CONCATENATE are simply the words we want to join together.
Let’s repeat the previous number-adding formula but with CONCATENATE instead:
=CONCATENATE(D5, E5)
Instead of 7184522037. the numerical sum of the zipcode and phone values, you’ll get 112037184510834, which is 11203 attached to 7184510834, as if they were words.
OK, let’s put some kind of symbol between them so that it’s easier to read:
=CONCATENATE(D5, " & ", E5)
The result is:
11203 & 7184510834
OK, there’s another convention to remember here: When wanting to join just literal text (i.e. not a special reference to a column name), you must use double quotes to enclose the string.
For example, if you do this:
=CONCATENATE("D5", " & ", "E5")
D5 and E5 are no longer treated as references to cells. Your formula will result in this:
D5 & E5
OK, enough demonstration, here’s what the CONCATENATE will look like for our purpose of getting an address field.
First, create a new column header, and bear with me, call it my_custom_column.
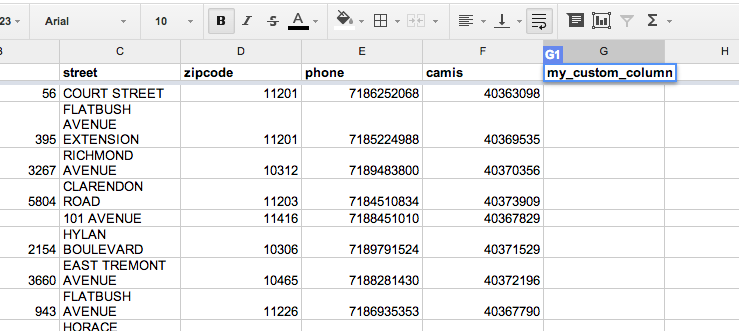
Then, in the next row (which should be row 2), type in this formula:
=CONCATENATE(B2, " ", C2, ", NY ,", D2)
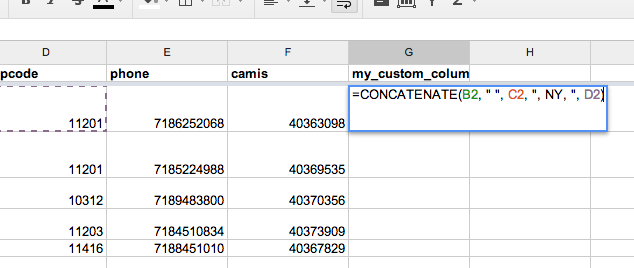
OK, that formula is a little hard to parse at first. If your building, street, and zipcode are in columns B, C, and D, then the above formula can be described, in English, as:
- Start off with the text in cell B2 (
building) - Add an empty space
- Then add the text in cell C2 (
street) - Then add the literal string
, NY ,– a comma, then a space, thenNY, which stands for “New York”, then another space, and then a second comma - Finally, add the text of D2 (
zipcode)
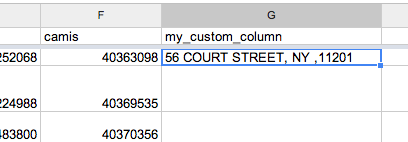
After typing in the formula, the value under your column header of my_custom_column should be something like:
56 COURT STREET, NY, 11201
Nifty!
Auto-fill a column
Now we just have to repeat that formula about 1,000 more times. Fortunately, Spreadsheets can automate that part, too.
Click your newly created cell and turn your attention to its lower-right corner, which should have a slightly-emphasized square:
Now move your mouse pointer over that corner. Your pointer should now turn into cross-hairs. Just double-click, and if you’ve done it right, the formula in the first column should repeat all the way down:
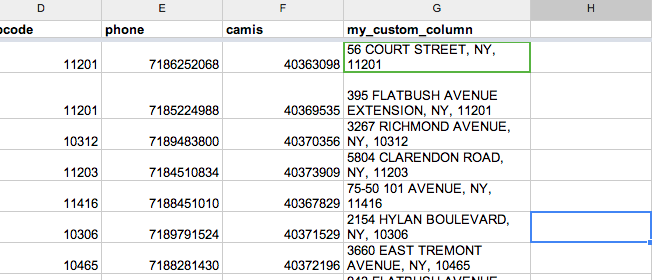
Pretty neat.
OK, onwards to Google Fusion Tables. We’ll be using Google Spreadsheets and its useful formula-based way of creating columns. If you’re new to them, they can be a little fussy and annoying. But keep it in perspective: with just a few keystrokes and mouse clicks, we created an entire new column of data. This technique works whether the dataset has 10 rows or 100,000. So yes, formulas are a pain, but they’re way better the old-fashioned data-entry.
Mapping data with Fusion Tables
Time to enjoy the fruits of our data labor. That column of location data will pretty much be the hardest part of creating an interactive map, thanks to the power of Google Fusion Tables.
It’s outside the scope of my lesson to describe all of the features of Fusion Tables. At a surface level, Fusion Tables seem no different than a spreadsheet…and in fact, the kind of data-enhancement we just did is pretty much impossible in FT, which is why we started out in Spreadsheets.
But when it comes to building Web interactives, FT provides some great out-of-the-box functionality. We’ll return to Spreadsheets to do some other data-preparation. But think of FT as the place we go to to make our data seen.
Create a new Fusion Table
Go back to http://drive.google.com and click on the red Create button. This time, click Fusion Table.
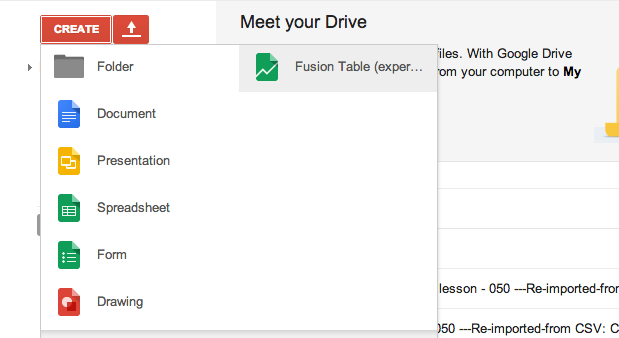
There’s a couple of ways to import data into a Fusion Table.
- From this computer: You can choose a text file of data to upload to FT.
- Google Spreadsheets: You can paste in a link to your Google Spreadsheet and FT will automatically import it in.
The second option – pasting a link to a Google Spreadsheet – is the quickest, but the first option is the most reliable.
I’ll show you both ways below. You will be repeating this process at least twice during the course of this lesson.
Piping CSV
As I walk you through the slightly tedious steps, be mindful of our purpose: we are simply piping data from one application to another – Spreadsheets is better for organizing, Fusion is better for visualizing.
And CSV (comma-separated values) is simply the plain-text format that both Google Spreadsheets and Fusion Tables (and virtually every other data application ever invented) can understand. Whenever one application fails to do everything you need, just take your data elsewhere (in CSV form).
Download as CSV
Go to the File menu, select the Download as item. This will give you yet another submenu of file formats to download your data as:
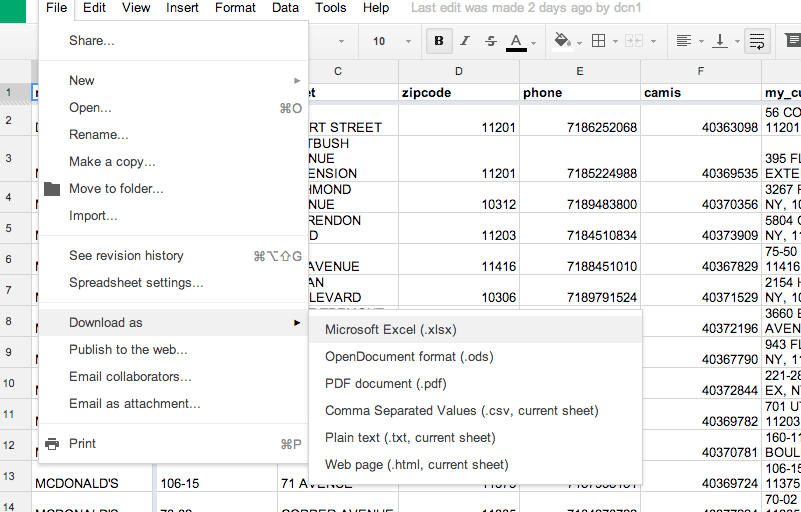
We want Comma-separated values. Why not, say, Excel? Well, because we don’t need an Excel spreadsheet right now. We want a Fusion Table, and Fusion Tables read CSV data (to hammer home the point, Excel also can read CSV data).
Depending on how your browser is set up, you’ll either see a prompt to pick a location to download the CSV file as. Or, it’ll just automatically download like any other file into whatever your default download folder is.
Now visit http://drive.google.com to Create a new Fusion Table.
Choose the From this computer option:
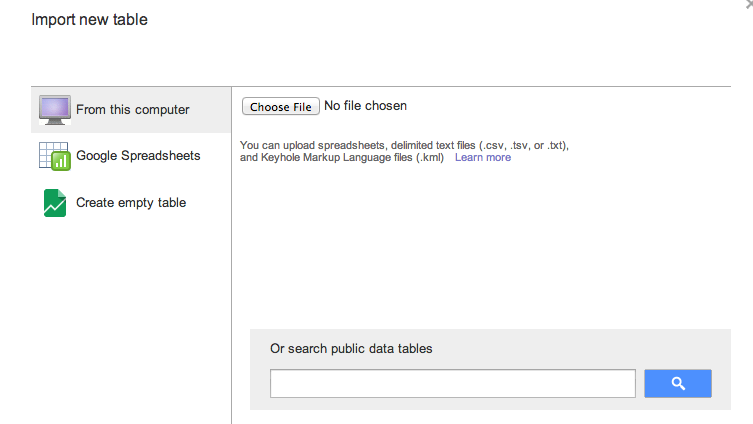
You will be prompted to choose the file for upload
After choosing a file, Fusion Tables will ask you about Separator character and Character encoding – you can just leave those options at the defaults.
Fusion Tables will then show you a preview of your data:
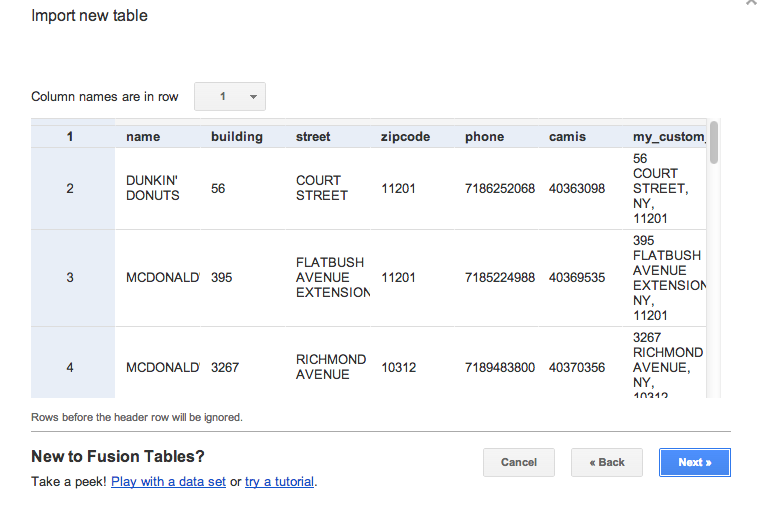
And then you can fill in some descriptive fields for your data. Just hit the Finish button when you’re all done.
It might take a minute for Fusion Tables to import your data before you’re the proud creator of a new Fusion Table.
You can read this next section for the other way to upload data, or skip it entirely.
Import via Google Spreadsheets
This is the quickest way to get from Google Spreadsheets to Fusion Tables. But it only works if your data is already in a Google Spreadsheet (obviously). And it often chokes on large datasets.
However, for our restaurants data, we should be OK.
So navigate to the browser window with the Google Spreadsheet you were working on, copy the URL, and paste it in the field where it says, “Or paste a web address here:”
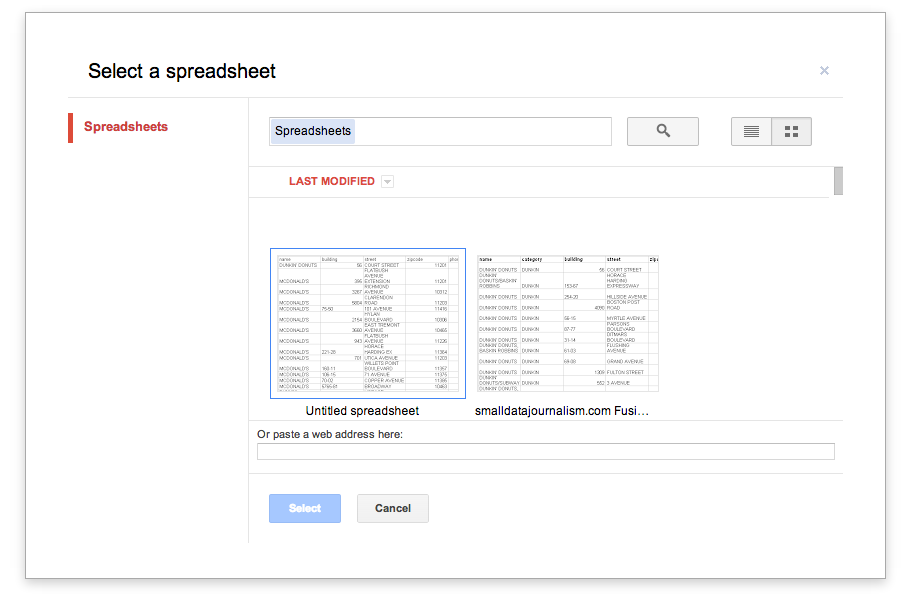
The dialog boxes that follow should be relatively straightforward and you shouldn’t have to change anything:
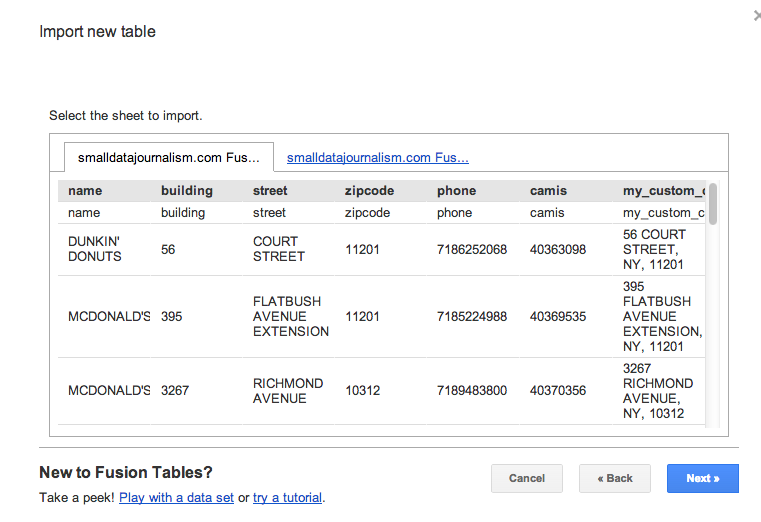
Voila, here is our data in Fusion Tables:
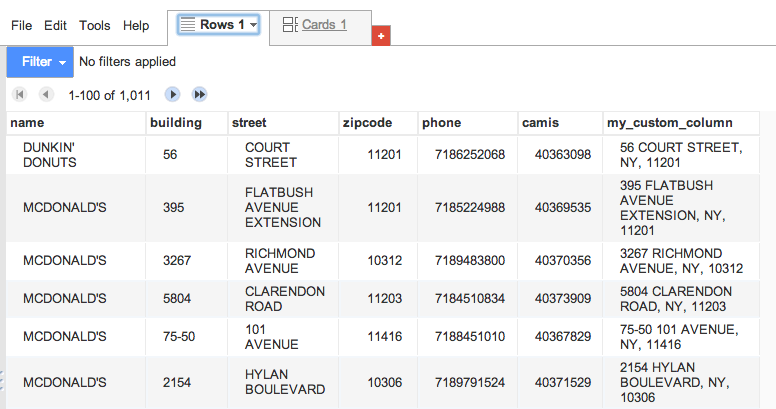
OK, now we’re in Google Fusion Tables. Time to map our data!
Column types in Fusion Tables
If you followed my previous instructions, the column containing a geocodable address should be labeled my_custom_column. Why did I pick such a useless name?
Mostly just to screw around with Google’s smart text algorithm. And to illustrate a point. Had we named the column something like location, Fusion Tables would’ve guessed (correctly) that the column contains geocodable data and then would have begun geocoding it onto a map.
That’s what we want, of course. But I want to show you how to manually set what column gets geocoded.
First, move your mouse over the right-side of the my_custom_column header. A down-arrow will appear; click it to pop up a new menu and then select the Change… item.
You should now see a form with several fields you can edit. The one we care about is Type. Currently, my_custom_column should have the type of Text. Change its type to Location.
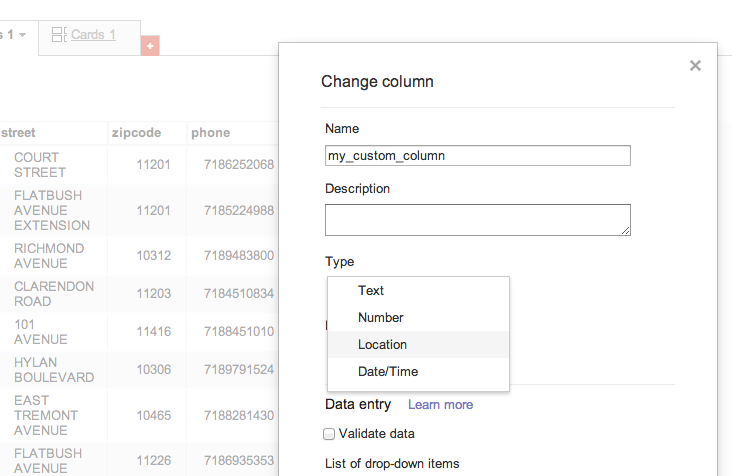
To be brief: even though everything in our data is technically text, you can have Fusion Tables treat it different by column. In this situation, we want FT to see the my_custom_column as a “Location”. For our purposes, this means that Google will attempt to map the points.
Geocoding
Save the changes you made to the my_custom_column. When you return to the main table view, you should see the entries in my_custom_column highlighted in yellow. This is Fusion Tables’ way of saying, “this text describes a location and we’re busy geocoding it for you.”
In the tabs of your table, which so far include Rows and Cards, you should see a red-colored tab with a plus sign +
Click it and you’ll see the option of Add map. Click that and you should see a screen like this:
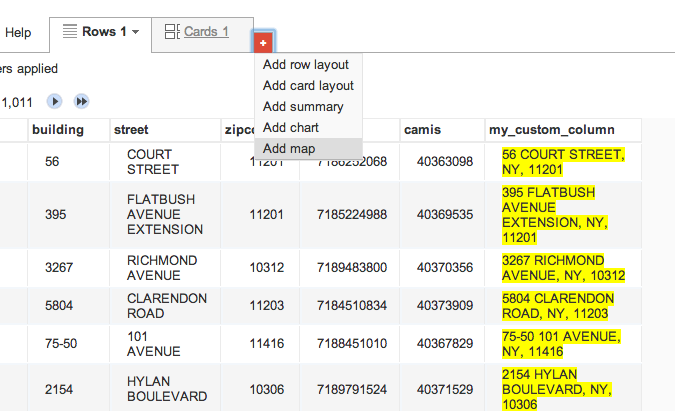
You have created a map view but you can’t see anything yet because Google has to first geocode those 1,000+ addresses we gave it. This may take 15 to 20 minutes, so go get some coffee.
Play with the Google map
Look at what came from our humble spreadsheet of data; A map!
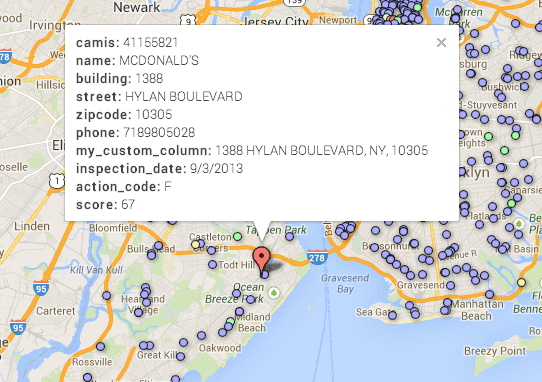
OK, it’s not too impressive in the default view because it’s so zoomed out. Why is it so zoomed out? Because some of the points are mapped way out of New York, even into Canada!
Bad Google! But wait…click on any of those outliers to see what it contains:
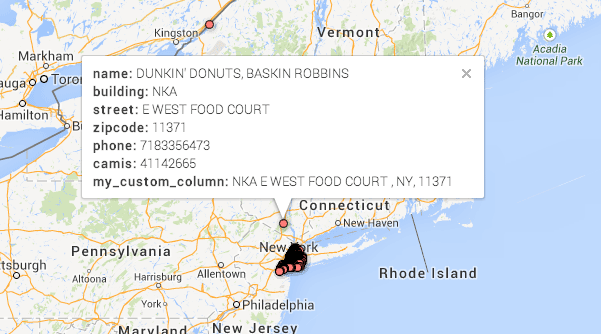
OK, so that address is a bit ambiguous, and it’s understandable why Google didn’t geocode it correctly. Even with a solid data source like the NYC Department of Health, we see that data is never perfect. In fact, data is almost always riddled with errors and inconsistencies. Dealing with that is one of the most difficult and soul-killing parts of data journalism.
But screw that, let’s go back to explore our cool map. Keep zooming in until the map is focused on New York City:
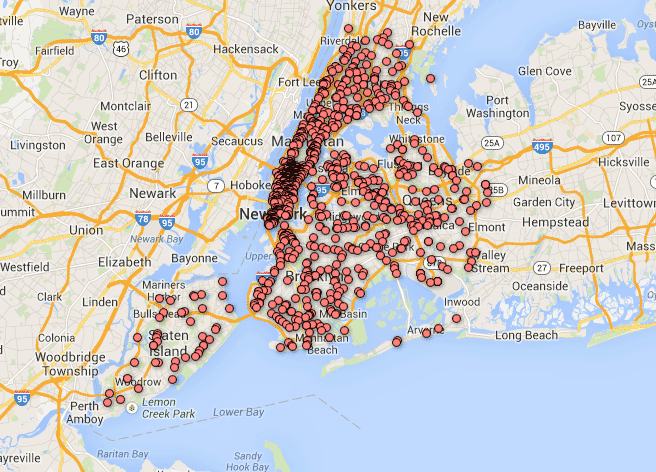
Look at that fat mass of fast food franchises!
Map styles
![]()
Filter the data (and the map)
It’s pretty neat that Fusion Tables built us an interactive, clickable map. Unfortunately, we still don’t have enough data to do anything interesting. The map itself is cluttered with a mob of nondescript red dots.
Before we get into Fusion’s most powerful feature, let’s try filtering the data.
Click on the blue button in the top left of the map labeled Filter. This should bring up a selection menu of your data column headers.
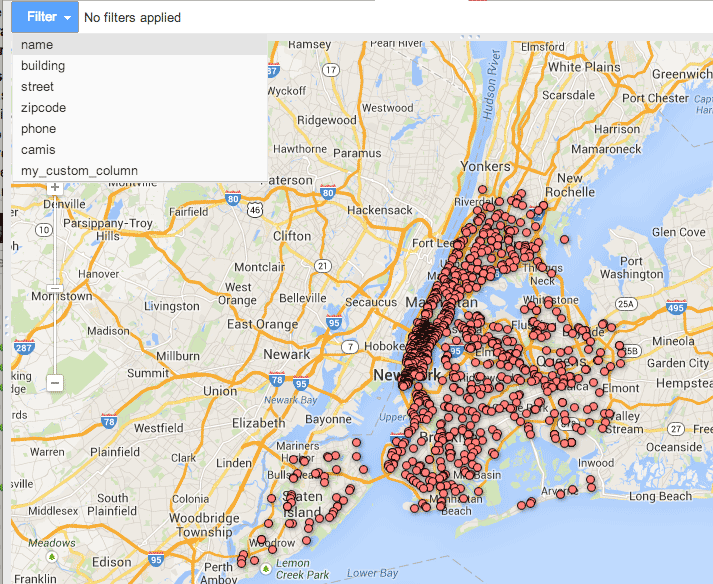
Click the option name. This gives you a form field to fill in. Type in a partial name, like “STARB” (for Starbucks). As quickly as you type, Fusion Tables will try to autocomplete.
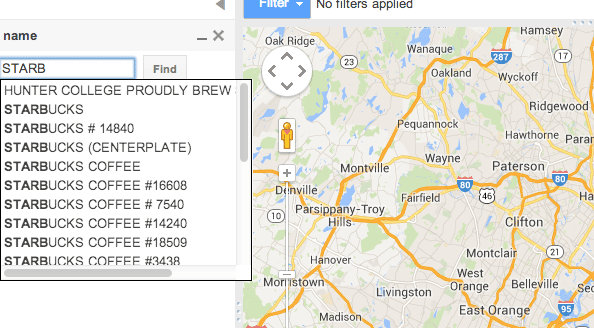
But don’t auto-complete. Instead, leave your partial term in the text field and then click the Find button. The map view should update showing fewer dots. If you click on each dot, you’ll see that the map now only shows datapoints which have a name that includes STARB.
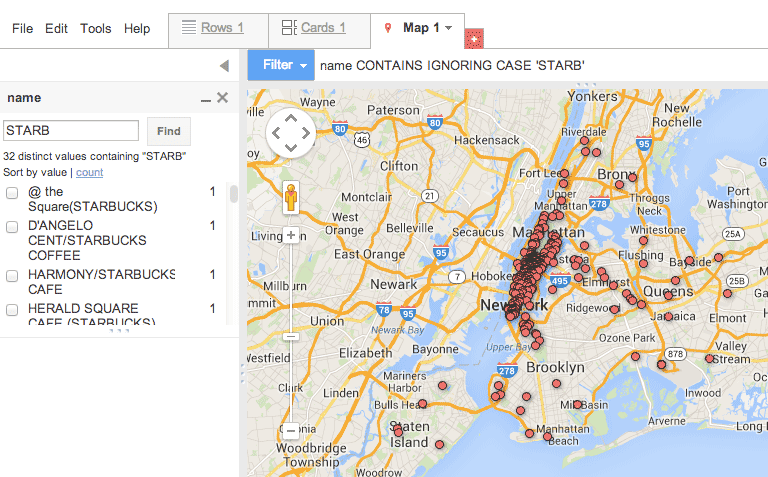
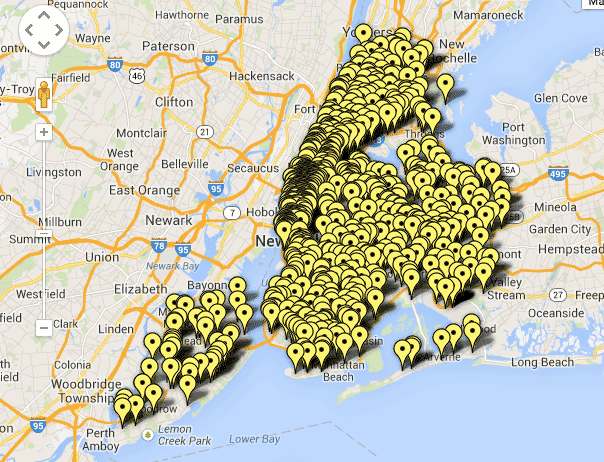
Pretty cool, we can now see the number and distribution of Starbucks versus McDonalds vs Dunkin’ Donuts.
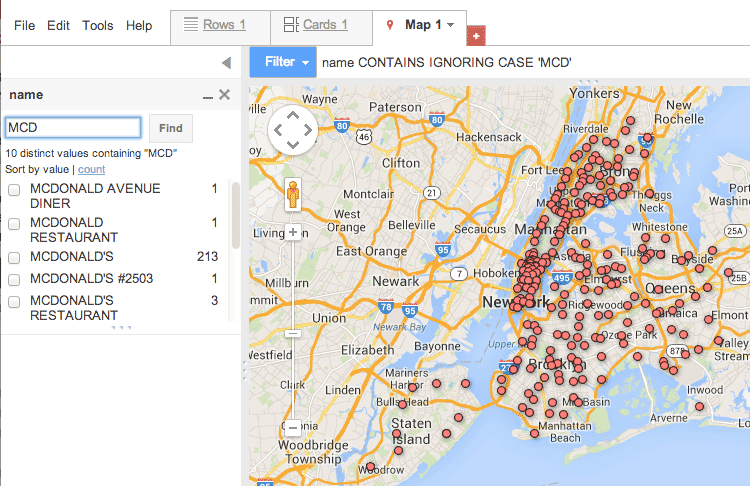
Here’s McDonalds:
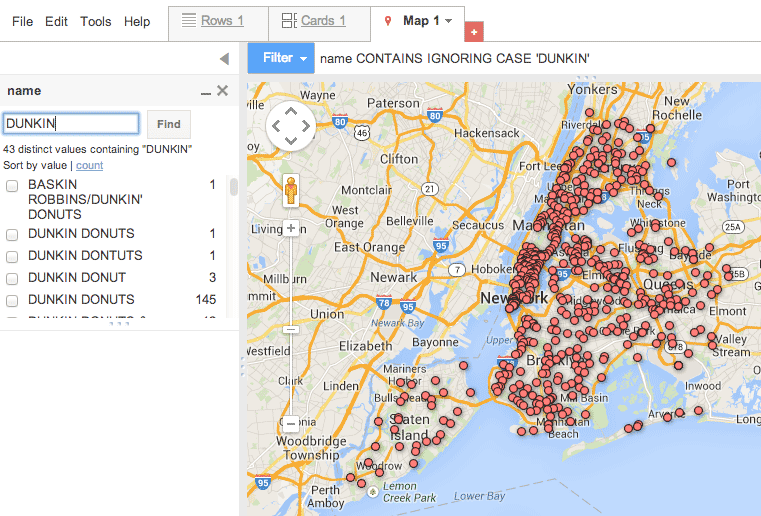
And Dunkin Donuts, which eclipses them both in franchise count:
Before we move on, click the X button in the filter menu so that all the datapoints are redrawn on the map.
Merging data with Fusion Tables
Alright, the map was cool, but the killer feature of Fusion Tables, in my opinion, is the ability to merge datasets.
Remember that we actually have two data tables. One is simply the list of restaurant establishments, which we just imported into Fusion Tables and mapped.
But the fun data – their health inspection reports, is in its own table. This is how it comes in the original NYC-DOH dataset because each establishment could have multiple reports. I’ve pruned the inspections to include only their latest scored inspection. But the reality remains: we have two separate lists that we want to merge together.
Import the Inspections table
You can download a CSV of the inspections data here. There’s no need to do any data cleaning with it. Just import it straight into Fusion Tables via the instructions I listed earlier.
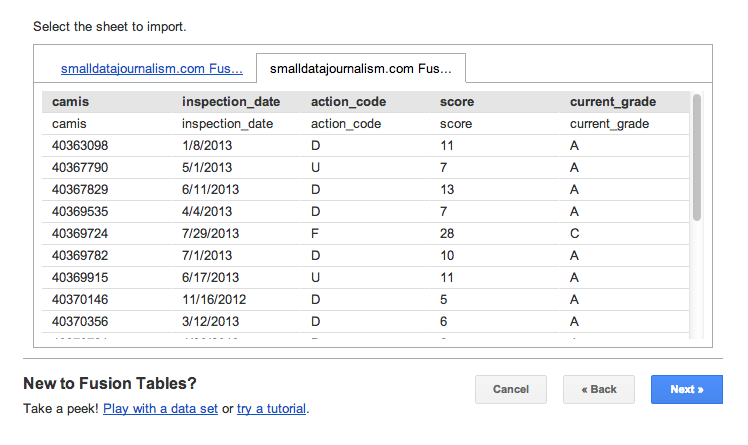
Now that we have two Fusion tables, one for inspections and one for restaurants, we just have to merge them so that we can see how each place did in their most recent (as of early October 2013) health inspection.
Foreign keys and unique IDs
But merge on what exactly? How do we know which report belongs to which establishment?
In this situation, it’s easy. You may have noticed in the table of restaurants a column named camis. I don’t know what that stands for, but it seems to be a unique identifier used by the NYC-DOH to keep track of each business.
If you look at the inspections table, you won’t see the names or addresses of restaurants, but you will see a column for camis numbers. In this case, the camis numbers are a foreign key. Thik of it as a way to link up with data from a “foreign” table: if you have a foreign key that matches the unique identifier of a row in another table, then the two rows can be joined together.
Just as I advised in the formula-writing part of Spreadsheets, think of how you would join these two tables the old-fashioned way: looking for the camis in the restaurants table, then searching for a row in the inspections table with that camis, and then, finally, copying and pasting the rows together.
Imagine doing this a thousand times.
Merging on a single field
Fusion Tables, as you might guess, makes this process extremely easy, and with just a few steps, we can greatly expand the dimension and detail of our restaurant data.
(Note: if you’ve ever used proper database software, such as SQL or even Microsoft Access, this section will annoy you because Fusion Tables is not as flexible or powerful in joining tables. But for a cloud-based point-and-click solution, it’s pretty good.)
First, click on File in the menubar and then click on the Merge option.
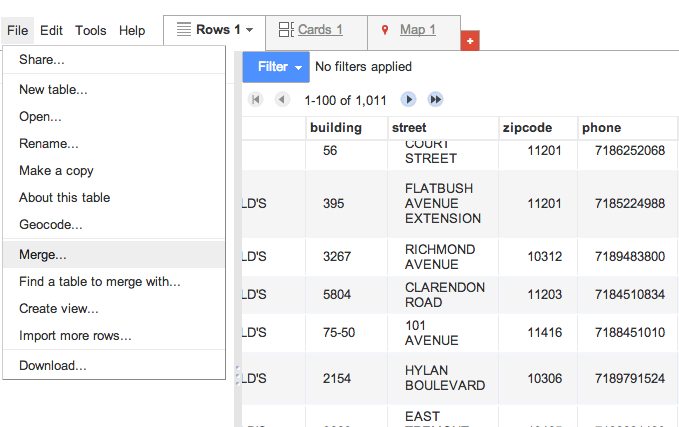
Fusion Tables will present you a list of spreadsheets already accessible to your account, with the most recent ones listed first. You should see the spreadsheet we were just work on at top:
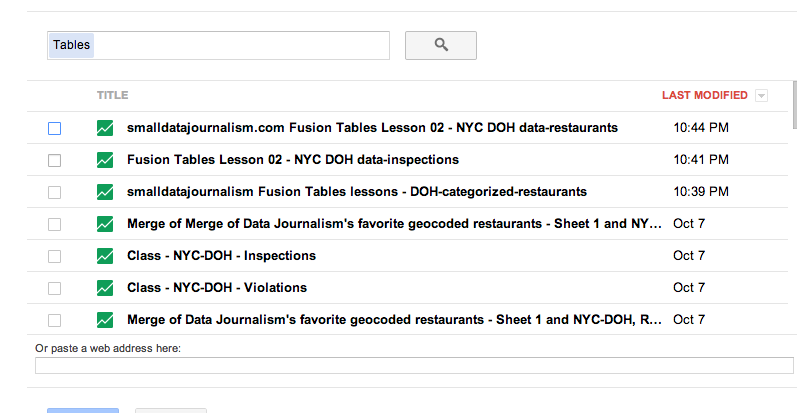
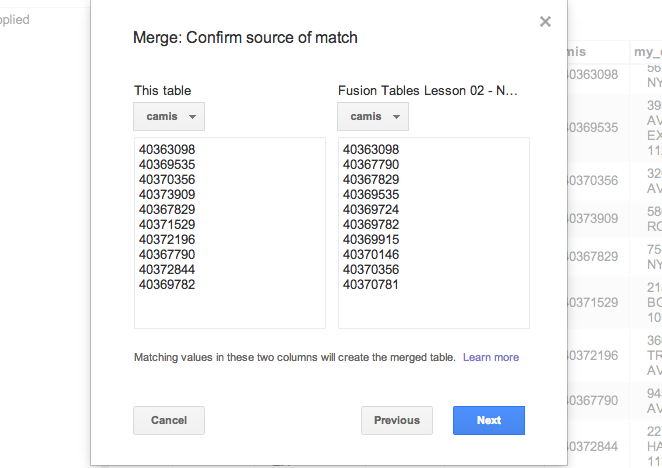
Next, Fusion Tables will ask you to Confirm source of match. This is where you choose the keys to join the table together. By default, FT just choses the left-most columns in each table, which in our case, is name in the restaurants table and camis in the inspections table.
The preview shows that these keys do not make sense:
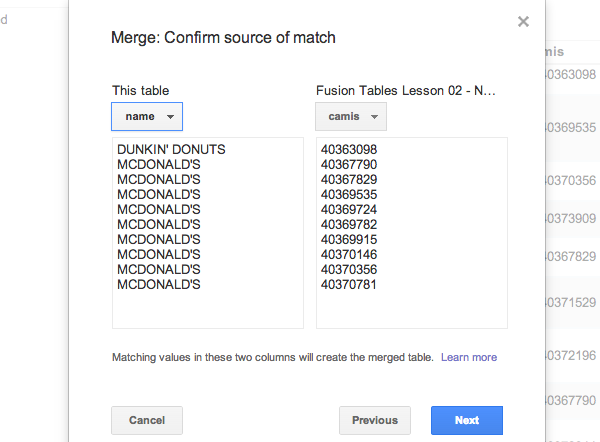
So change the selection for the restaurants table to camis:
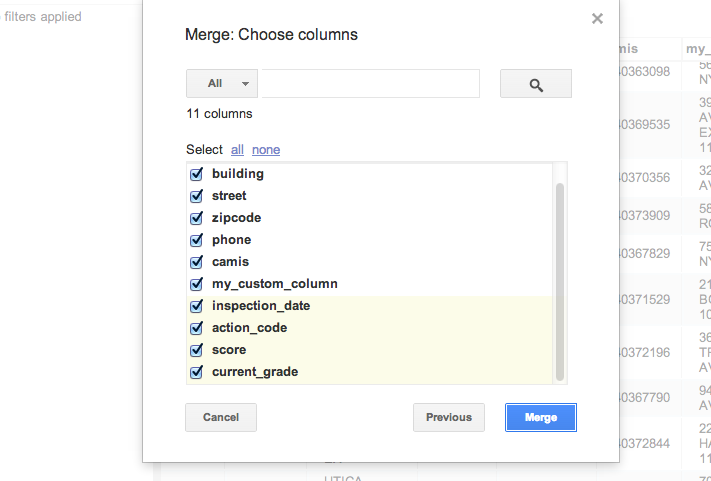
The result of our merge will be to make one sheet out of two sheets, so this screen asks you to choose which columns of the two tables should be in the merged table:
And this is how you know it worked:
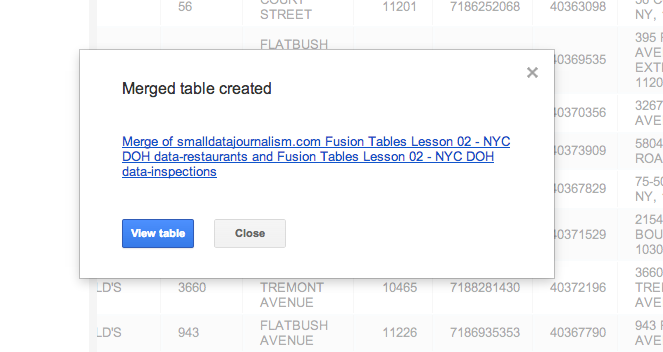
When you visit the table, you will see that your restaurant data now has four new columns dealing with inspection data: inspection_date, action_code, score, and current_grade
Classification of map markers
Now that we have the score column, we can attempt a classification of the data: that is, we classify the restaurants based on the score of their inspection results, with closer to zero being good, and larger numbers being bad.
This is easy enough to do by sorting the column and scanning the text of the rows. But we can also classify data visually.
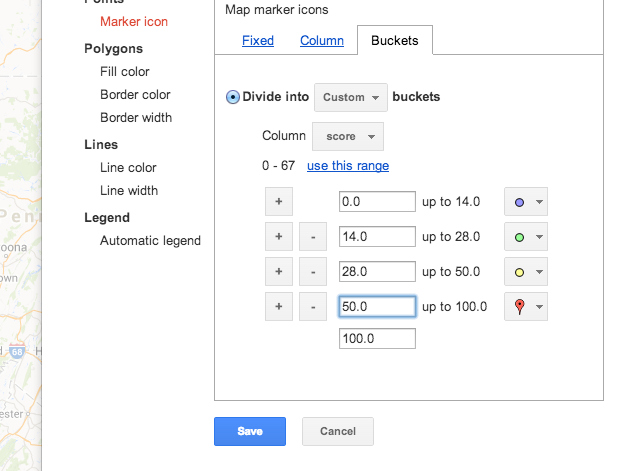
Buckets and thresholds and colors
Go back to the map we created. Go to the Change map styles… option and select the Buckets option. Then select the score option as it is the only numerical column that makes sense to divide into “buckets.”
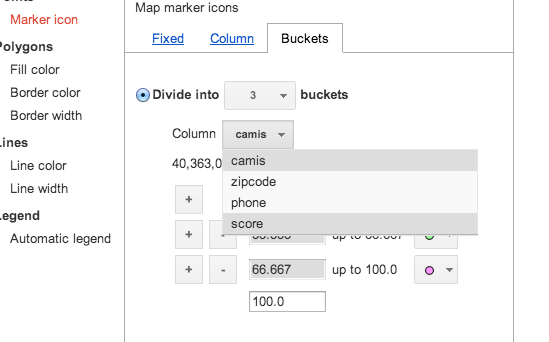
You can think of “buckets” as thresholds, that is, what is the cutting point between an A and a B grade, and to what color of marker should we assign to make it easy to locate the A- and B-graded restaurants on the map?
I’ve chosen a grading curve and color system based on the NYC-DOH’s system: less than 14 points is an A, 14 to 27 is a B (note, the bucket range says “up to 28”, so that doesn’t include 28). And a C is 28 points and above.
However, I’ve also added an arbitrary cutoff at 50, so that restaurants at this level are marked with a big red dot.
Now check out our more colorful map (note, some restaurants do not have associated scores and appear as the default small red dot):
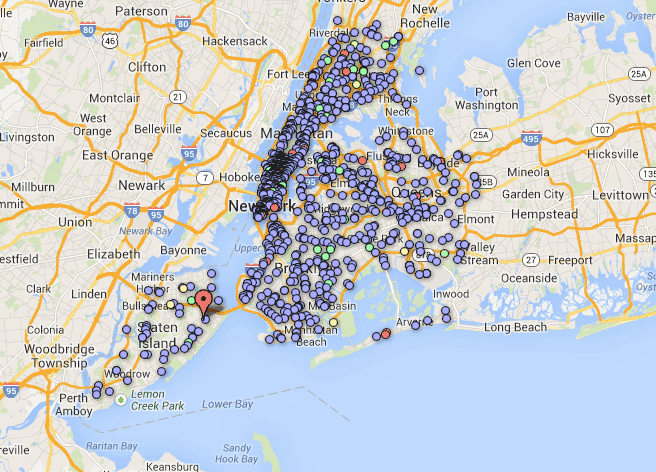
What can we surmise? There is one Staten Island McDonald’s that has racked up an impressive number of points, but otherwise, these franchise restaurants are nearly uniformly clean.
Were you expecting otherwise? If you thought quality of food and beverage correlated with health grades, you would be wrong. If anything, when a company owns several hundred locations in New York City alone, they’ve probably come up with a standardized way to meet the city’s health requirements.
Summarizing data with Fusion Tables
The map is interesting and does show the big picture. However, a map is not great for analyzing the details. As Matt Ericson writes in his must-read essay, When Maps Shouldn’t Be Maps: “…the reflexive impulse to map the data can make you forget that showing the data in another form might answer other — and sometimes more important — questions.”
So what are the more important questions here? Well, obviously, which of these chains is cleaner than the others, for bragging rights!
So what we need is a summary of this inspection data.
This guide is already too long so I won’t give this topic the proper detail (i.e. I’m not going to even try to explain Pivot Tables.
Basically, the problem is this: we have the ideal kind of data: a flat table, with one record per row. That’s a lot of detail. However, sometimes, we want to step back and see the big picture. The most common example of this is to get an average for the data, which, in our case, would be an average of the scores column per restaurant chain.
So let’s try it out:
Click on the Rows tab. Then hover your mouse over the tab until a little down-arrow appears. Then click on that down-arrow to bring up a menu and choose Summarize…
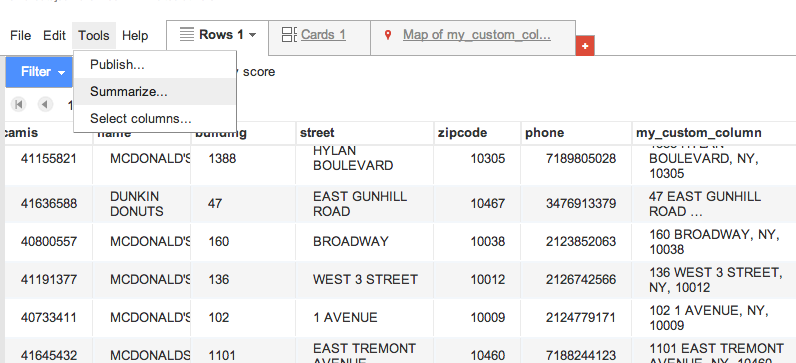
We have three chains here: Starbucks, McDonald’s, and Dunkin Donuts, and these types are reflected in their names. So we want to summarize by Name
And what we want to summarize is the score of their health inspections. Click the checkboxes for Minimum, Maximum, and Average, because it’d be interesting to see the best and worst scores of each company.
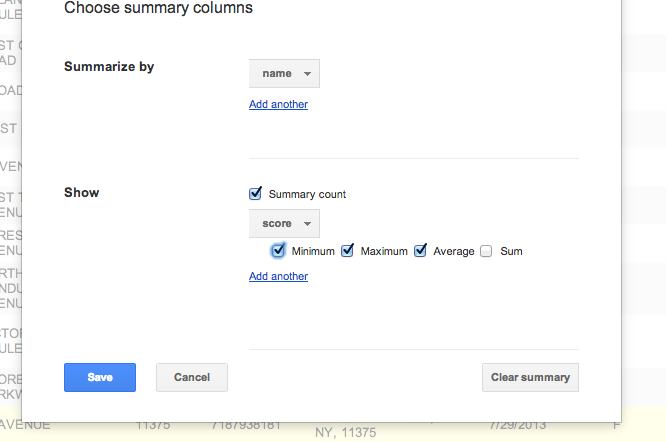
Now hit Save and your table will have a different view:
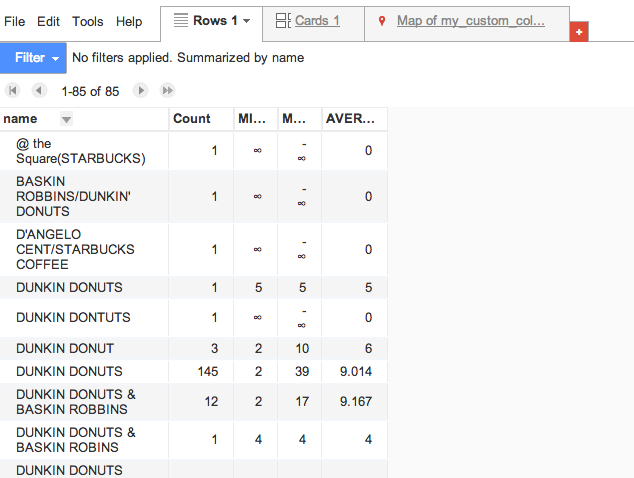
OK, if you think this is confusing, then you have followed my steps correctly. The summary view here is confusing, and that’s because our data is just plain messy. We wanted to summarize by name, but our restaurants aren’t named nice and neat. Instead of just uniformly-named DUNKIN DONUTS locations, we have: DUNKIN' DONUTS & BASKIN ROBBINS, DUNKIN DONUT, and the poorly-entered in, DUNKIN DONTUTS.
Fusion Tables thinks that all of those are different kinds of business (OK, technically the donuts and ice-cream combo is different) and puts them into their own little groups.
But we just want three groups.
Ah, the joys of dirty data.
The summarizer of Fusion Tables is kind of dumb. It will only match exact terms (upper and lower case is ignored though), so even though you know DUNKIN DONUTS and DUNKIN DONUT really refer to the same chain, your state of the art computer is thrown off by that single S. If you recall back to when we were filtering data, we only entered partial strings to match the restaurants.
So what can we do? We’ll take a brief tour into the dirty world of messy data cleaning.
Before doing that, go back to the Summarize… screen and click the button to Clear summary to see all your data again.
Data wrangling with Google Spreadsheets
Data wrangling is loosely defined as the work we do to convert raw data into something useful. We did it previously by turning the restaurants’ address information into a single location column. And we’ll do a similar kind of work to categorize our varied restaurants listings into three categories: Starbucks, Dunkin Donuts (in this example, I’ve actually shortened it to Dunkin), and McDonald’s.
Why do we have to do this? Because data isn’t perfect. It’s filled with typos and people’s differing opinions and sometimes, computer-based errors. So we have to “wrangle” the data to make it easy to analyze. The analysis we want to do here is to simply summarize scores by Starbucks, Dunkin Donuts, and McDonald’s.
Fusion Tables is not good for this kind of work. So navigate back to your Google Spreadsheet – the one that contains the restaurant data with the custom locations column.
First, make a copy of this spreadsheet. You can find the command in the File menu.
Now, in this copy of the spreadsheet, you can delete all of the columns except for name and camis. For the following examples, I have left all the columns in but inserted a new column near name, which I have labeled category.
Formulas with regular expressions and conditionals
We’re going to write a new formula now, and this one will generate a value based on the contents of the name column.
To review the problem here: we want to get all the restaurants named something like DUNKIN – whether it is DUNKIN DONUTS, DUNKIN' DONUTS, or DUNKIN DONUTS & BASKIN ROBBINS – to have the same term, or category, if you will.
How would we do this without a computer? Easy: We’d look at the name value and see if something like DUNKIN is in it. And if so, then we enter DUNKIN DONUTS into the category column.
We don’t want to do that 1,000 times though, so we use a formula. In particular, we use a function named REGEXMATCH
REGEXMATCH
What does REGEXMATCH mean? It refers to regular expressions, which, in my opinion, is the most important basic tool besides spreadsheets that a data-journalist/cleaner can learn (programmers use them a lot too). But you probably won’t because they seem boring (I’ve written a free PDF guide here for the intrepid).
No matter, for our purposes, REGEXMATCH is just a fancy way of matching text, and we don’t need to use its most fancy features.
In the respective category column, enter in this formula:
=REGEXMATCH(A2, "DUNKIN")
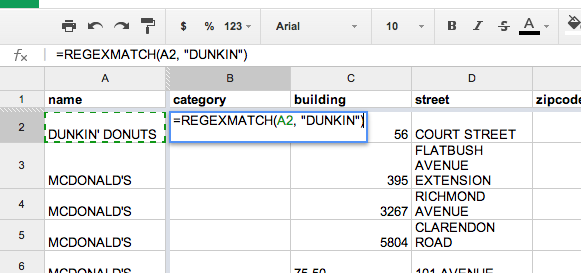
The first parameter to this function is the cell we want to search, the second parameter is the actual text that we want to search for. In this case, "DUNKIN" does indeed appear in "DUNKIN' DONUTS", so our function returns a TRUE.
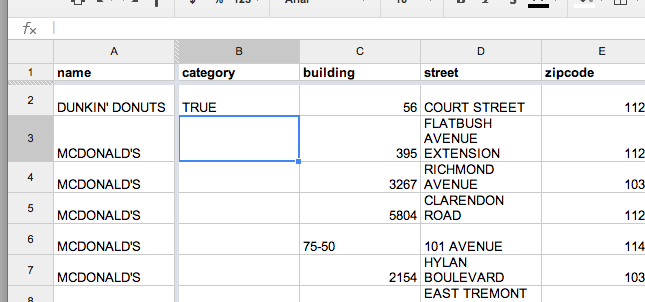
That’s not quite what we need, because TRUE is not one of our three categories, i.e. DUNKIN DONUTS, MCDONALD'S, and STARBUCKS
IF
This is where the IF function comes in – it lets us specify what to print if a certain value meets certain conditions. In our example, we would express this as:
If the
namevalue contains “DUNKIN” (viaREGEXMATCH), then print “DUNKIN” into the correspondingcategorycolumn.
And this is how you express that as a spreadsheet function:
=IF( REGEXMATCH(A2, "DUNKIN"), "DUNKIN", "")
The IF statement takes in 3 parameters:
- A function or value that is either
TRUEorFALSE - If
TRUE, the second parameter is printed - If
FALSE, the third parameter is printed
So if that REGEXMATCH evaluates to TRUE, you will see a DUNKIN as the result of that formula. If not, a blank value is the result (this is what two quotation marks with nothing in between them is equivalent to).
OK, so how do you get that for all three categories we need? Well, we just use another IF statement – but pass it in as the third parameter to the original IF.
In other words, the third parameter can just be another IF and REGEXMATCH combo:
=IF( REGEXMATCH(A2, "DUNKIN"), "DUNKIN", IF(REGEXMATCH(A2, "STARBUCKS"), "STARBUCKS", ""))
That gets us STARBUCKS. Now we just throw the third statement in:
=IF( REGEXMATCH(A2, "DUNKIN"), "DUNKIN", IF(REGEXMATCH(A2, "STARBUCKS"), "STARBUCKS", IF(REGEXMATCH(A2, "MCDONALDS"), "MCDONALDS")))
Head hurt yet? I’m moving through this fast because explaining the flexibility of functions could be its own guide. If you are still confused, you should write out the three IF statements (one for each restaurant chain) and then combine them manually. Otherwise, you should just copy-and-paste the above into your spreadsheet.
=IF( REGEXMATCH(A2, "DUNKIN"), "DUNKIN", IF(REGEXMATCH(A2, "STARBUCKS"), "STARBUCKS", IF(REGEXMATCH(A2, "MCDONALDS"), "MCDONALDS")))
UPPER
OK, one more thing. As it turns out, not all of the restaurant names are in uppercase, and REGEXMATCH is case-sensitive:
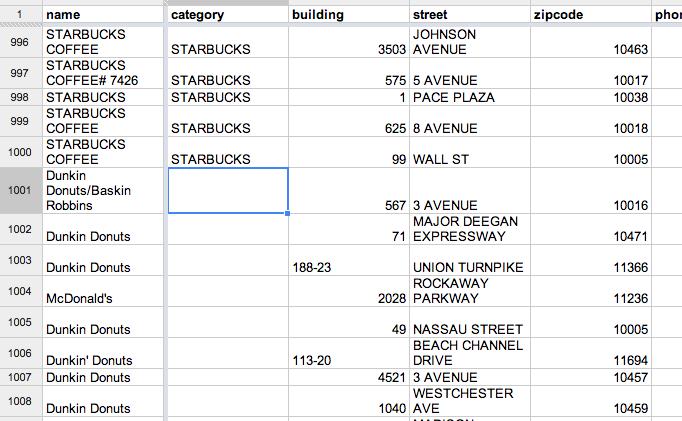
Remember that computer programs in general are just finicky and won’t think that “DUNKIN DONUTS” is the same as “Dunkin Donuts” without further help.
The easiest way to do that is, in our already massive formula, use the UPPER function to uppercase all the cell values before comparing them with REGEXMATCH.
Here’s the head-hurting formula:
=IF( REGEXMATCH(UPPER(A2), "DUNKIN"), "DUNKIN", IF(REGEXMATCH(UPPER(A2), "STARBUCKS"), "STARBUCKS", IF(REGEXMATCH(UPPER(A2), "MCDONALDS"), "MCDONALDS")))
Again, it’s not so bad if you break it down. But moving on…
Remember that double-click on the lower-right corner trick we used to auto-fill an entire column? That works here too.
Lookup tables
So what did we do all of that for? To create a lookup table. That is, when Fusion Table has a value, such as DUNKIN DONUTS & BASKIN ROBBINS, our lookup table lets it look up what category that DUNKIN DONUTS & BASKIN ROBBINS corresponds to, i.e. DUNKIN.
In a sense, we’ve created a new data table. And now we need to merge it into our previous Fusion Table.
Merging problems
OK, this is where software problems can crop up. Fusion Tables is powerful, but it’s a relatively young piece of software by Google. So the reasons that it may hang unexpectedly may be through unfinished design or just plain cruel chance.
For instance, in this current example, Fusion Tables simply would not let me merge my new spreadsheet of categories with my existing Fusion Tables. I got this unresponsive screen instead:
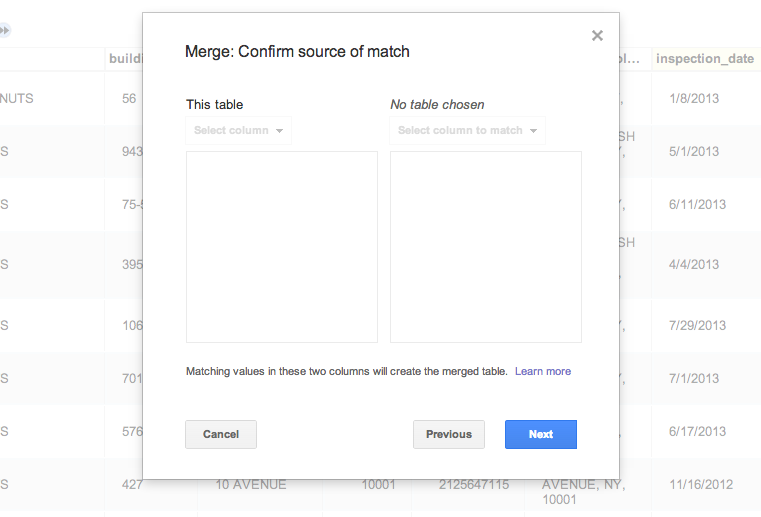
For reasons that could either be sensible or just momentary technical flaws, Fusion Tables puts certain constraints on what you can do with a merged table. In the screenshot above, I’ve apparently run into a software flaw. But there may be legitimate technical reasons why your merged table won’t be as flexible as you like.
Export to CSV
It’s annoying, but we can deal with it. Remember that everything we’re working with is just text. So let’s export our Fusion Table (the one that was the merge between inspections and restaurants) into a plaintext CSV file:
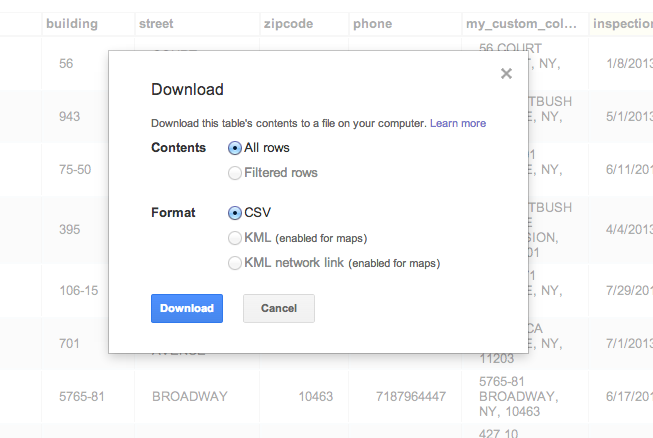
Import as CSV
Now re-import it into Fusion Tables by creating a new table and then choosing a file from your computer (in this case, our just-downloaded CSV file:
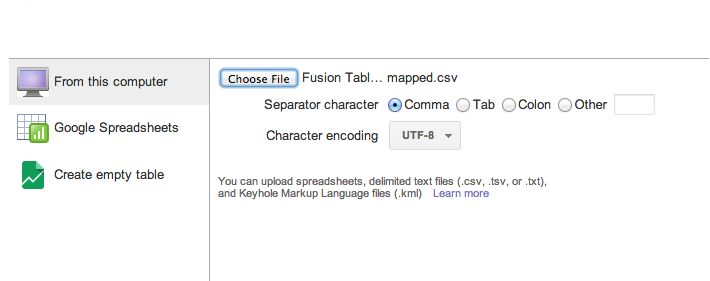
And after that, import that table of restaurants with category that we created in Google Spreadsheets into Fusion Tables.
(In this category table, I also ended up deleting every column except category and camis, which you can do via the Change column action.
)
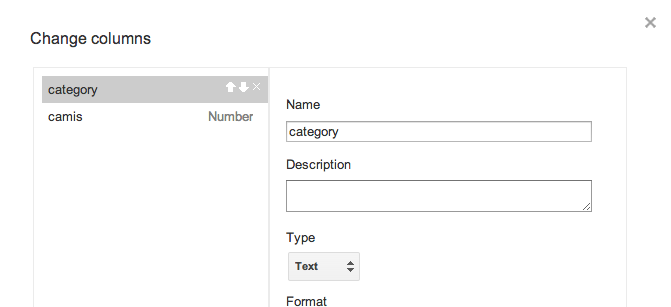
It ends up looking like this:
Re-merge
OK, almost there. So now we have two Fusion Tables that we care about:
- A table consisting of restaurants and inspections that we just uploaded from a CSV file to get around a Fusion Table technical limitation (it may have to re-geocode the locations again)
- A table consisting of the restaurant information but with a
categoryfield. For clarity sake, I removed all the columns exceptcategoryandcamis.
Merge the two tables together, just as we did before. Whether or not you, like me, removed all of the columns in the second table except for category and camis, you will still join the two tables via the camis column.
A proper summary
So what was the purpose of all that data wrangling? It was to easily summarize the data. So now that we’re in Fusion Tables, find the Summarize feature again:
For the Summarize by dropdown-menu, choose category (in our previous attempt, we used the name field).
The field that we want to Show will again be score
Check the checkboxes for Minimum, Maximum, and Average, and hit the Save button.
Now we’ll get a proper summary:
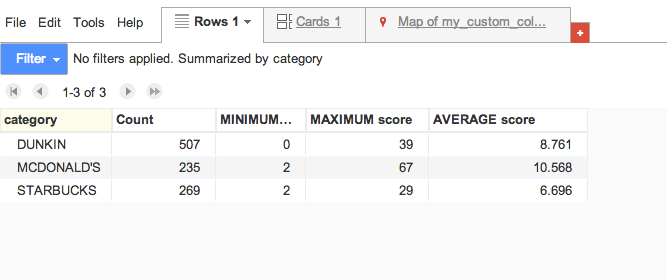
OK, nothing too interesting. Starbucks has the lowest average score with 6.7 per inspection and McDonald’s the highest at 10.6 – but that’s well below the 13 cutoff for an “A” grade from the city, so well done mega-chains!
More map classification
Without adding more data, there’s other ways we can visualize this data geographically. The most obvious way is to base the markers off of our category column, so we can see how all three chains are distributed across NYC.
We kind of did it by filtering the data. But let’s see what it looks like all together.
If you go to the Change map styles… screen, you’ll see that there is a Column tab:
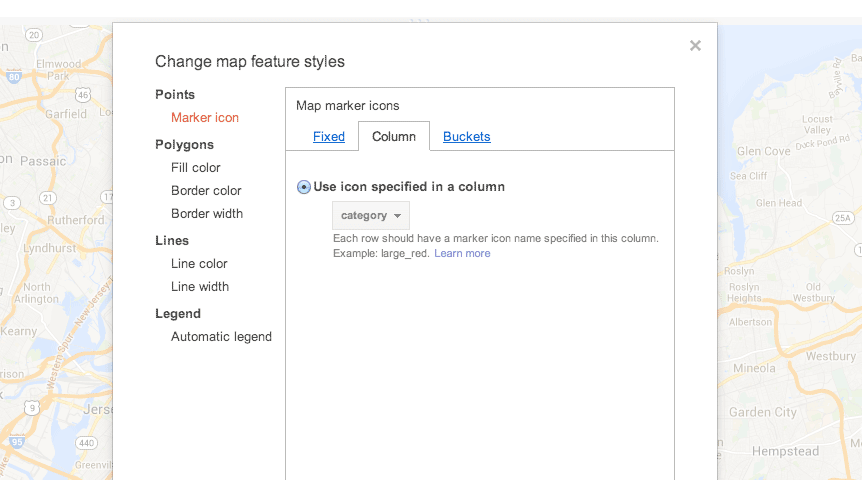
Problem is, we can’t just use category. Fusion Tables wants a column that specifies a name of an icon, such as small_red or large yellow. You can read the full instructions here.
You can even specify icons that aren’t just color icons:
![]()
So how do we get a column of icon names into our data set? By now, you should know the answer: merge tables
Your new table will simply consist of three rows, one for each kind of restaurant we have. And then you merge that new table with our existing table (you may need to do the export to CSV and re-import trick yet again).
I leave that as an exercise for you. You can check out Google’s tutorial here: Tip: Merge tables to apply map styles by column
In the end, your map will look something like this:
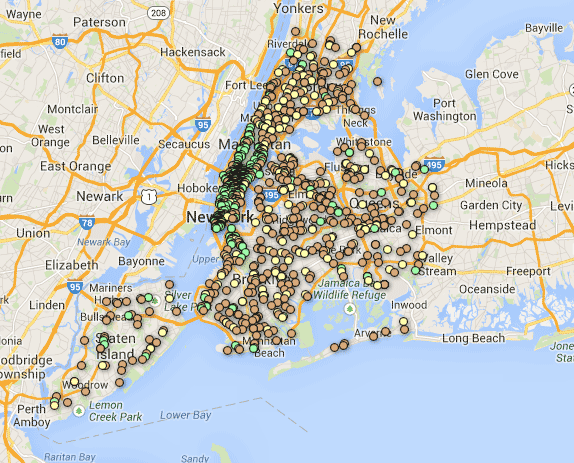
Starbucks is in green, McDonalds in yellow, and Dunkin Donuts in brown. You can see the a full webpage version here.
I was surprised at the market penetration of Dunkin’ Donuts. Wherever you are, no matter what borough, you may never be more than a mile or two from glazed heaven.
Publishing
While analyzing and cleaning data can be a fulfilling joy (if you’re crazy), most journalists aim for publishing things. Fusion Tables also makes this easy and gives you a variety of options for displaying your data, either as tables or maps.
Click any of the tabs, such as the one for your map, and choose the Publish… option:
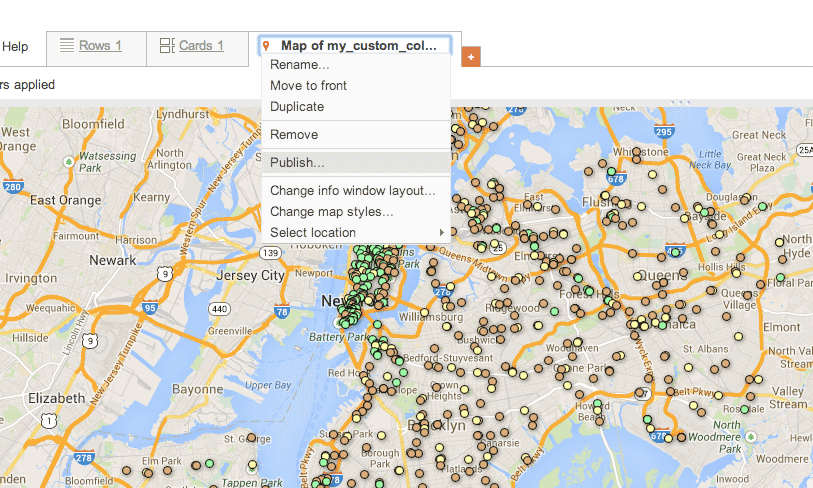
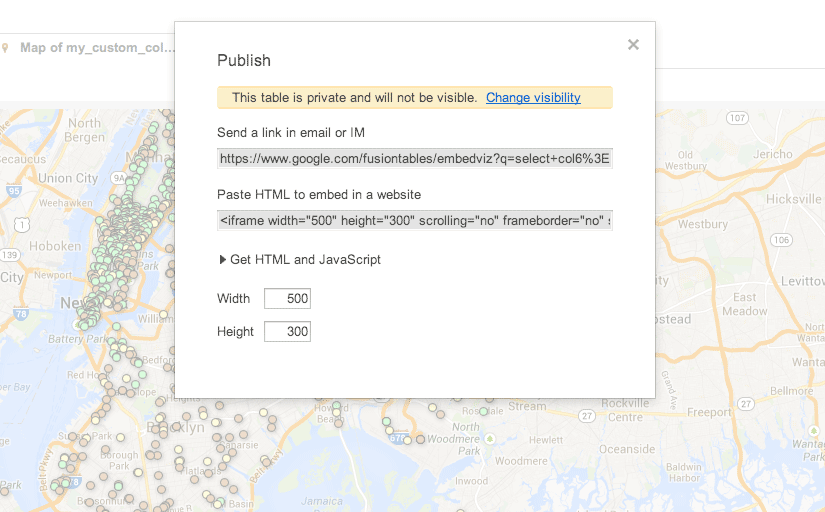
You then have to make the map public. And after that, you have a couple of options for embedding the map data into a webpage. The iframe option is likely to be the most compatible, with most blogging sites.
Here’s the webpage I made using Google Fusion embeds. I’ve combined both the tabular data and the map, plus some explanatory text.
If you’ve gotten this far and are completely lost, here’s the link to the Google Fusion Table that contains the final data and maps.
Want to know how to publish a webpage from scratch? You can read my beginner’s guide to using Amazon S3 for web hosting here.
The next iteration
So there’s nothing groundbreaking in this data, but this was just an exercise and one of the simplest ways that this inspection data can be examined. In the NYC-DOH data, there’s an entire table of violations that I didn’t join. Want to find which of these locations had mice and/or cockroaches? Just get the database of violations and merge them into your inspections table.
Fusion Tables (along with Google Spreadsheets and Excel) have some limitations, but if you combine their features (by moving data back and forth), you can do some pretty impressive (and shareable) data work.
If you’re interested in doing more complex analysis and visualizations with Fusion Tables, I highly recommend reading WNYC data editor John Keefe’s blog, where his Fusion skills have tackled everything from political donations, hurricane evacuations, and Census demographics.
I hope you’ve gotten a sense of what data analysis entails: there’s lots of annoying data cleaning, but once you get the hang of it, you can manage datasets of hundreds to hundreds of thousands of rows. And it’s not too hard to make a useful interactive graphic out of it.
There’s a lot of tedious, application specific steps in this specific example. But don’t focus on memorizing the steps. Focus on why we did something to the data and how it was necessary to get to the next step. Whether it’s Google Spreadsheets, Excel, SQL, or the next coming of dBase, the concepts of data integrity and structure will be the same.
If you’re interested in data journalism, check out my curated list of data journalism articles and books. You can also follow me on Twitter at @dancow. If you have questions or comments, feel free to email me at dan@danwin.com.